Scale Modelling Central
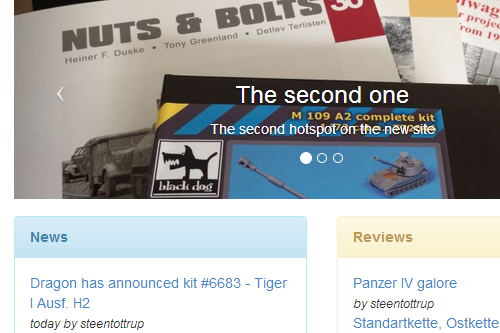
The site is a news, resource and community site for people collecting, and maybe even building, scale models (the plastic kits you got as a kid, that you glue together and maybe even paint to make them look like a miniature version of an actual plane/tank/what not).
The Challenge #1
The data we store for the kits are quite complex, with collections of simple and complex types as part of the kit object.
Of course this could be modelled into a number of tables in a relational database, and actually was before we moved to a document database.
Unfortunately that would be a bad idea. When ever you need to get a kit 'record', you also need all this extra data. That would mean several inner and outer joins on every read.
The more data you have, the bigger the server you need. Even worse, if the database gets really big, there's no way of splitting the data out across servers.
The Solution #1
When using a document database, in this case MongoDB, you do not store data as records with set a number of columns, you store documents.
Documents are complex objects that can contain regular simple data like strings and integer, but also collections of simple and complex types.
So when we need to display information about a kit, we fetch all the data needed in one single query.
This of course means that we do have some redundancy, but that is a lot better than having to do several reads!
The Challenge #2
Being a community site, the solutions has to be ready for lots of users, and more importantly, the interactions of the users.
One of the things the users can do, is register the unbuild kits they have.
Trying to display the kit info fast is a bit hard when we also want to display the users who own that particular kit.
The Solution #2
You could argue that the information about which users own a particular kit belongs on the kit object. Especially when we want to display the information on the same page as the kit.
Unfortunately that would mean lots of more or less concurrent updates of the kit object, and would bloat the size of that document.
To avoid this bad use of the database, we store the information in its own collection/table. That way you'll get a lot of inserts into this collection, and a few deletes. Much better!
To not ruin the great performance we have when displaying a kit, we use asynchronous loads to show these additional information.
Now we can let the visitor know if he himself has a particular kit (in case he forgot), and we can let the visitor know who owns the kit, if he needs feedback or help.
If you actually need the extra info, you probably wont mind the less than one second delay you get before it has been loaded.
The Challenge #3
Not all shops are virtual/internet shops.
When you travel to a new city/country, you probably would like to go visit a shop that sells these hobby items.
So we need to locate shops close to a visitor's current location.
The Solution #3
Document databases, at least some (Lucene and MongoDB to mention 2), have been good at storing and querying data based on a location/distance for a long time.
So we store the longitude and latitude of a shop in the database, and when we need to locate shops nearby, we do a simple query with the visitors current longitude and latitude and a maximum distance.
It just works, and the really crazy part, you get the results really fast!
Visit Scale Modelling Central.